Answer: A simple way is by using the concept of revelation distribution into a Monte Carlo simulation framework..
The idea - presented in details in my paper on this subject, is summarized below (see also the animations after the topics):
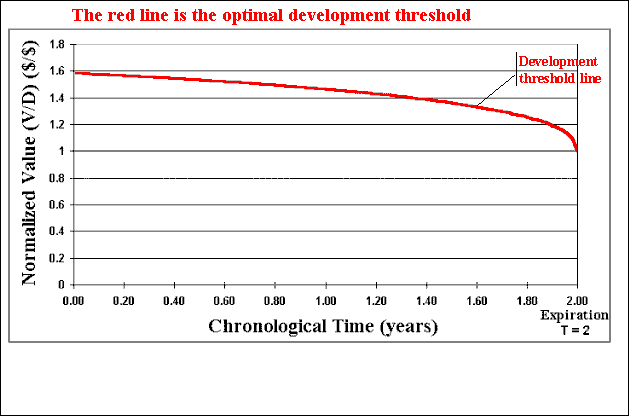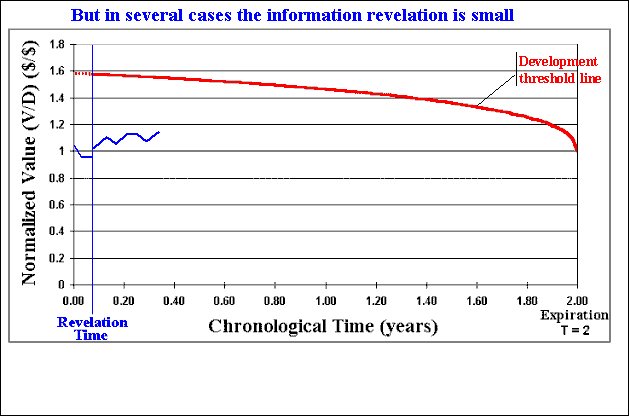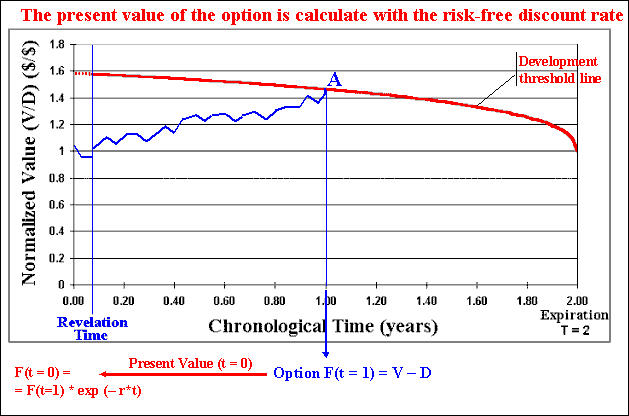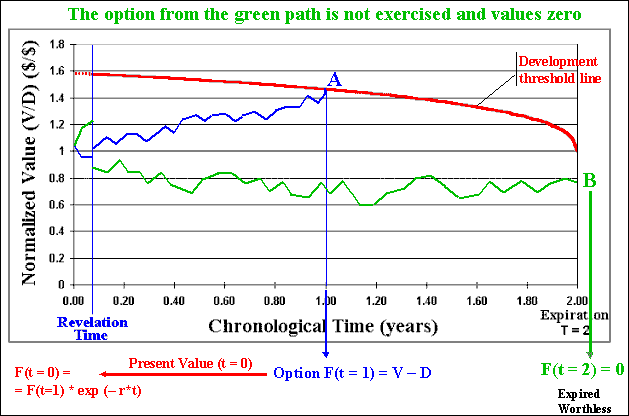
The animation below illustrates the methodology, which can be performed with the software Timing with Dynamic Value of Information. This chart of the normalized value of project V/D with the time, presents an example with time to expiration of two years and a time-to-learn of one month.
After N (hundreds or thousands) of sample paths we sum the options values obtained in each path (a lot of zeros and a lot of positive values) and divide by the number of simulations N. By subtracting the cost of the information, we finally get the real option value considering the investment in information and both technical and market uncertainties in a dynamic framework.
Note that we can perform the same calculus for several different alternatives of investment in information. In this framework, we can consider that the learning alternatives have different costs, different time-to-learn, and different benefits (captured mainly by the revelation distributions).
The framework is dynamic because consider the factor time: time-to-learn, time-to-expiration, and the continuous-time stochastic process for P. Our decision rule (V/D)* also depends on the time (because the option is finite-lived).
For additional information, see the page on Technical Uncertainty, Investment in Information, Information Revelation, and Revelation Distribution and the page on the software Timing with Dynamic Value of Information.
The first proposition is trivial - but very important as the limiting of a learning process, and it draws directly from the definition of prior distribution. The others three propositions are demonstrated in the paper appendixes
The second proposition is just an application of the law of iterated expectations. The third proposition is the central proposition because captures the revelation power of one investment in information, that is, the capacity of a learning process to reduce the uncertainty, which is directly linked to the revelation distribution variance. The last proposition helps the evaluation of different plans of sequential investment in information, permitting the application of martingale tools that is a well developed branch in probability and stochastic processes.
With the reasonable assumption that the prior distribution has finite mean and variance, Proposition 1 tells that even with infinite quantity of information, the variance of revelation distribution is bounded. This contrasts strongly with some real options papers that model technical uncertainty using Brownian motion, which the variance is unbounded and grows with the simple passage of time, which is also inadequate - this distribution changes only when new relevant information is revealed through investment in information.
About the last point, the figure below illustrates the difference of a continuous-time stochastic process (from a market variable like the oil price) and the evolution of a technical uncertainty (e.g., the reserve volume B). The figure shows one typical sample-path in each case along the time. The market variable changes with the simple passage of the time because every day investors expectations on the supply and demand are tested in the market, whereas the expected volume of a reserve changes only if new relevant information arrives from a new investment in information (in some cases due to new technology, but in most application it is even more dispersed in discrete points along the time).
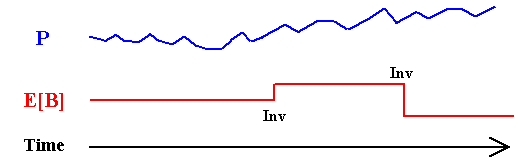
Hence, the technical uncertainty evolves in discrete-time fashion and in most cases is an event-driven process controled by the manager. That is, the manager has the option to invest in information and, if it is exercised, almost surely will obtain a new expectation for the technical parameter(s).
The above propositions allow a practical way to ask the technical expert in order to get the information necessary to model technical uncertainty in this approach. Only two questions:
Conditional expectation has strong theoretical and practical support.
Theoretically, E[X | Inf] is the best predictor in the sense that minimizes the mean square error.
It is also the best (non-linear in general) regression of the variable X with the information Inf. In addition, conditional expectation has a natural role in financial engineering: the price of a derivative is a conditional expectation considering the optimal management (exercise) of this derivative, where the conditioning is the information process along the derivative life.
In practical terms is much simpler to work with a single distribution of conditional expectations than infinite (for the continuous case) posterior distributions. In addition, even when we can write an algorithm to work in practice with the infinite posterior distributions, we don't know what scenario of each posterior distribution is the true value of X. So, our optimal decision at the stage that we know the posterior distribution (but not the true value of X), f(X | Inf = i), perhaps will use a scenario from this posterior distribution that minimizes the error. This posterior scenario is the mean of the posterior distribution, which is exactly our conditional expectation.
Sometimes is important to consider the residual uncertainty (e.g., the expected variance of the posterior distributions) in addition to E[X | Inf] in order to calculate (penalize) the expected value obtained with the decision based in E[X | Inf]. See in my paper on revelation distribution an example using a gamma factor (based on expected residual variance) to adjust the value obtained with a certain decision on the optimal capacity to install in an offshore oilfield with uncertainty about the reserve volume.
![]()